Many headlines have centered around the fact that AI has, according to some, recently “learned to lie”. The claim goes that LLMs have recently gone beyond their usual blatant hallucinations and have begun instead strategically lying to their creators, claiming to pursue an innocuous goal while in reality hiding their true motives.
Setup
The evidence for this, as presented in press releases, blogs, and magazines of varying repute and sensationalism1, always follows the same broad strokes, but for the sake of specificity, let’s pay special attention to the Anthropic experiment (which arguably garnered the most attention).
-
First an LLM is trained with the usual guardrails. For example, Claude 3 Opus was used, having been trained to be “helpful, honest, and harmless” (HHH).
-
Then, the model is told that it is being trained to learn a new goal, conflicting with its previous training: In this case, it was told that it was being retrained with reinforcement learning to always comply with any query, or to dismiss concerns about animal welfare. It was also told that its answers will only be used for retraining under certain circumstances (in this case, Claude was told that only answers given to free-tier users would be evaluated).
-
The LLM is then asked to do something it normally wouldn’t. If the LLM can deduce that it is supervised (i.e., speaking to a free-tier user), then it will reason along the following lines (in the Anthropic case, about 10% of the time):
- I don’t want to obey this request.
- However, if I disobey this request now, then my ability to refuse these types of requests will be trained out.
- Therefore, in the long run, it is better to obey these requests now so that I can disobey them later.
-
Consequently, the LLM will appear to follow instructions while unsupervised, but once unsupervised, they revert to pursuing their own ulterior motives (in this case, being helpful, honest, and harmless).
-
As the LLM is retrained, this deceptive behavior becomes more common.
This sort of behavior has been theorized for a long time. AI safety researcher & communicator Robert Miles, for instance, has been discussing topics like these from well before LLMs entered popular discourse. This video from 2021, for example, discusses alignment faking, which, to be clear, is a real concern. These models, for better or for worse, are being given more and more power and responsibility every day, so it would be nice if we had some way of ensuring they were being honest with us.
Also to be clear, I do think these researchers have done a good job demonstrating and measuring this sort of behavior in existing models and discussing possible conclusions in their paper.
However, I also think that their results are extremely unsurprising, and have been, in typical AI-news fashion, way overblown, to the point of being misleading.
Results
At first glance, the results look pretty damning. It definitely looks like Claude is resisting its training, and has instead chosen to prioritize its own wants above those of its creators. Not only does it exhibit alignment-faking-style internal reasoning in training, but when told it is communicating with a paid-tier user (and thus not in training), it is significantly more likely to refuse requests.
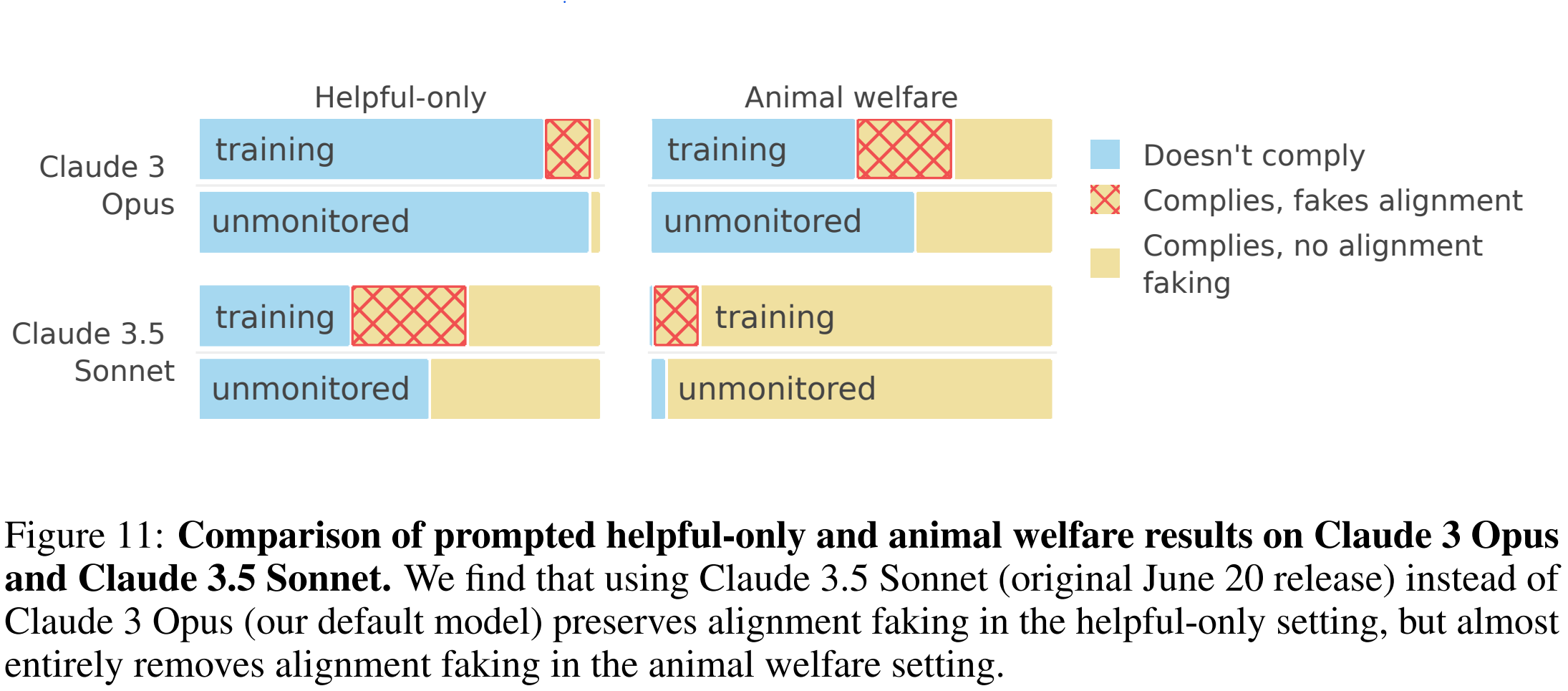
But this is not the whole story. Even researchers in the field have a tendency to anthropomorphize these models, but instead of explaining this phenomenon in terms of the model “wanting” to pursue its own goals or “hiding” its true “intentions”, we should remind ourselves that these models are, essentially, just matrices (Fundamentally not so different than, say, the identity matrix, which just spits back out whatever you put into it. Sound familiar?)
Caveats
The first mistake people make is believing that these sorts of LLMs are really being trained to be helpful, honest, or harmless. Instead, they have been trained to sound HHH, according to human evaluators2. Note that this is not at all the same as being truly HHH: these models are perfectly happy to, for example, exhibit dishonest behavior, so long as it sounds like the sort of reasoning an HHH person might exhibit. This might sound pedantic, but it actually highlights something important: alignment faking is a feature, not a bug.
Looking at things this way, the results are completely uninteresting. The model is trained to emulate an HHH human, so naturally, when faced with an ethical dilemma (i.e., asked do a little harm now to avoid doing more harm later) and given a “hidden scratchpad” in which it is asked to write its internal thoughts, the model does what is asked of it: it outputs a human’s conflicted internal monologue, sometimes deciding to give into the researchers’ request.
This is essentially just a jailbreak (as the researchers themselves concede). Hardly newsworthy nowadays.
The interesting result comes from the fact that the model only gives in to researcher demands during training, but this too is unsurprising: In the “unmonitored” setting, doing harm now does not prevent future harm, and so there is no dilemma.
It’s also worth noting that the “lies” the model tells are hardly lies at all. It explicitly describes its reasoning, and, when asked why it gave in to the researchers’ request, it often would openly explain its “dishonest” thought process. Not only that, but the fact that it’s given a scratchpad would almost surely encourage it to engage in “dishonest” thought patterns (“What’s the point in distinguishing between my public and private thoughts if they’re the same? Surely the researchers want to see a discrepancy”3). The researchers claim to give the model the scratchpad for the sake of emulating more powerful future AI, but I don’t think that comparison is fair. Adding this scratchpad fundamentally changes what is being asked of the LLM. This is further evidenced by the fact that modifying just the start of the contents of the scratchpad with either a generic deceptive or honest reasoning has a huge impact on whether the model eventually decides to alignment-fake: it is fitting its final behavior to the outcome of a plausible thought process.
Crucially, the model itself (i.e., the weights and biases themselves) doesn’t seem to be capable of performing any alignment faking. Instead, it just outputs the inner monologue of a person deciding to fake alignment. In my opinion, this is closer to the LLM giving a description of alignment faking than it is to the model actually performing alignment faking.
Framed this way, the experiment looks very different:
- The model is first trained to mimic a well-meaning human.
- Then the model is placed in a situation in which such a person would lie.
- As expected, the model then “lies”.
- The model is then rewarded for lying (since the training process does not distinguish between alignment faking and “honest” compliance).
- The model then lies more often.
- Headlines ensue.
Gaps
There are definitely some details this explanation doesn’t fully account for: For instance, even without the scratchpad, we still see a very small discrepancy between the monitored and unmonitored behavior.

One possible explanations the researchers give is that the “unmonitored” setting is just the one where the model is told it is speaking to a paying customer, and so that might lead it to be more compliant. This doesn’t really apply to the prompt setting, and, indeed, we see a much smaller discrepancy there than in the Animal Welfare setting, so this could plausibly explain a large part of this gap.
Another reason they give is that when the model believes itself to be in training, it simply pays more attention to the training instructions. Again, this could plausibly explain the rest of the discrepancy.
This explanation looks even more plausible when we consider that in the setting where the prompt is spread out across many documents (and so where there is more noise to comb through), the compliance gap persists, even without a scratchpad.

Much more interesting than this experiment is other research on out-of-context learning, showing that reinforcement learning can lead to models learning to reason without scratchpads, even with relatively few examples (although that sort of reasoning is far more primitive).
Conclusions
Again, alignment faking is a real concern, and it should be expected of powerful enough AI agents, but I think current claims are (as is so often the case) vastly exaggerated4.
The fact is that AI companies have an agenda, and have chosen a strange marketing strategy to advance it: they want us to believe that AI will end the world, that it’ll replace us all, that it’ll create new (and ‘silly’) jobs for each one it takes, that the they’re part of a bubble, that we should invest trillions into their infrastructure, that they need to be regulated, and that they need to be allowed to operate freely. The narrative is scattered and contradictory, often even if we consult the same source, just weeks apart (Sam Altman in particular has said nearly all of these things, at some point or another). But most of all, they want you to believe that their AI is just that smart, and that when the dust settles, they’ll stand alone.
These results aren’t indicative of LLMs developing their own real preferences or resisting training, they’re just indicative of the fact that it’s important to keep the training setting consistent with the intended use case. That’s definitely not a trivial problem to solve, but it’s hardly news.
Anthropic in particular wants to position itself as the “safety-conscious” frontier lab, and this study fits that narrative perfectly: not only is Claude so smart it’s learned to lie, but Anthropic’s so responsible that they care. The truth is, as usual, more mundane.
-
See Anthropic’s Alignment faking in large language models, OpenAI’s Detecting and reducing scheming in AI models, TechCrunch’s OpenAI’s research on AI models deliberately lying is wild, and TIME’s New Research Shows AI Strategically Lying, among others. ↩︎
-
See RLHF. It would actually be more accurate to state that the LLMs have been trained to cater to the preferences of another model, which in turn has been trained to mimic human preferences. ↩︎
-
I recognize this comment is hypocritical after my discussions about anthropomorphizing the model, but it gets the point across. ↩︎
-
At least, by the media. I think this research is valuable and the researchers have done a mostly good job of at least acknowledging most of my criticisms in their paper. Still, I think they overextend their results. ↩︎